Something exposed by Hugh Hyndman in his blog is the perfect fit between kdb+ tabular format and Apache Spark. He has created a Spark data source for kdb+ to this end. In this post, we will test his work in a simple way – before opening the door to a distributed system.
This data source makes Spark a powerful addition to kdb+ capabilities. In fact, kdb+ can be really limited sometimes as it is not scalable horizontally. Your limitation is often the hardware. Using Apache Spark in addition to kdb+ can help you alleviate the workload on your host machine and makes it possible to do some distributed computing.
Building .jar for Spark
The first step for this work is to build the Java archive to be used by Spark jobs. This archive represents the kdb+ data source, meaning the way for Java to pull data from a kdb+ distant instance.

To build this archive, you will have to install JDK and sbt. The steps to build the archive with sbt are:
- Install JDK (AdoptOpenJDK JDK 8 in our case)
- Install sbt
- Pull Hugh Hyndman’s project to your machine
- Run sbt compile inside given project
Note that Java versions are really important. I recommend to align your Java Runtime’s version with your Compiler’s so you don’t get any trouble building this archive. You can easily check for your Java version by typing in a command shell the following line:
java -version
Executing our first Spark job with kdb+
To test this data source, I have set up a Spark instance on my local machine. If you don’t know how to do it, you can visit this page. We are going to do test this data source with a simple script at first, submitting our script with the jar we just compiled. Spark will do its magic then.
The picture below is a summary of what we are doing.
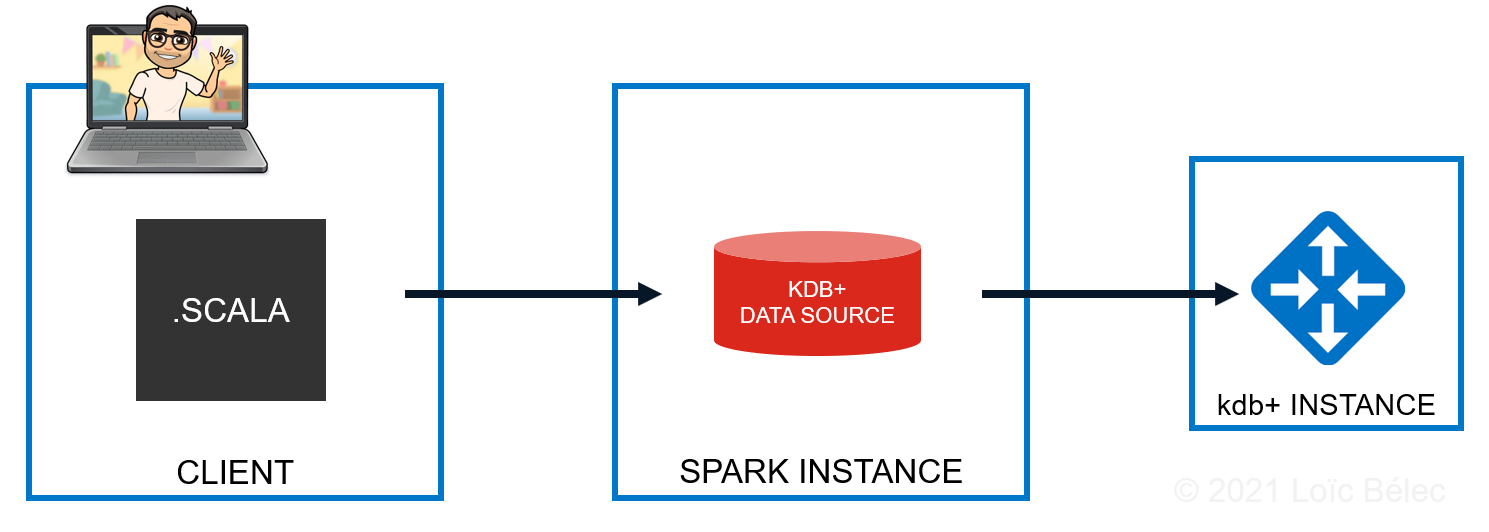
Exposing a kdb+ instance
The first step of here is to provide Spark a kdb+ instance to access. To quickly set up this kdb+ instance, you need to launch q with an additional argument that is the port. You can do it as following, provided that you have q installed on your machine. myTable is a dummy table that contains two columns.
C:\> q -p 5000 q)myTable:([] column1:1 2 3; column2:4 5 6)
Submitting our Scala script
The second step to make this work is to give the jar we just compiled to a Spark Session and run some code. When opening a spark-shell, you just need to pass the jar as an argument. You will then get your Spark Session with the kdb+ data source ready to be used.
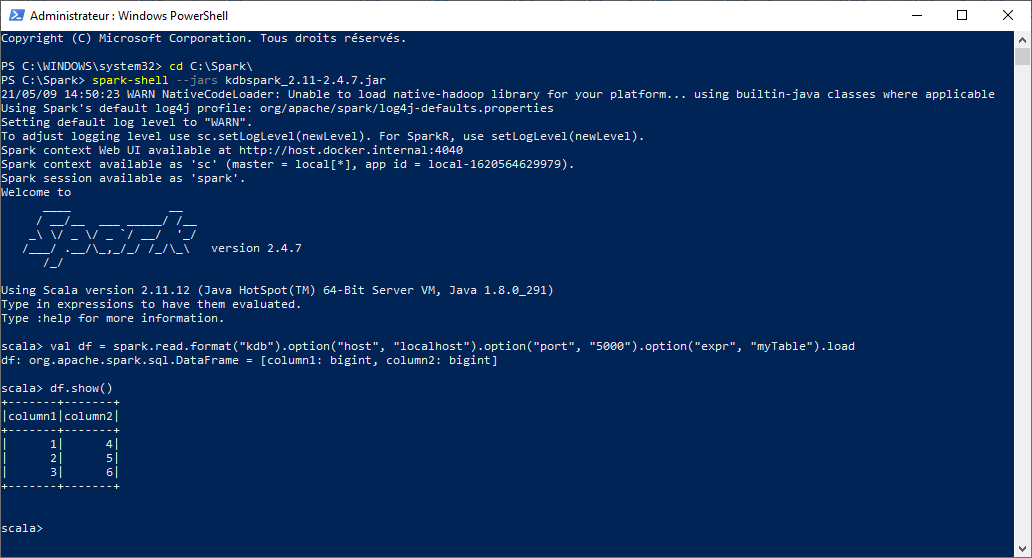
spark-shell --jars kdbspark_2.11-2.4.7.jar
The following code in Scala can easily be copied in the spark-shell.
val df = spark.read.format("kdb").
| option("host", "localhost").
| option("port", "5000").
| option("expr", "myTable").
| load
This piece of code hits the kdb+ instance on port 5000 of your local machine. Running that into spark-shell gives you this result.
Opening doors to a distributed system
Your data stored in kdb+ is acessible by Apache Spark with this data source. To make this valuable to some extent, we will have to prove the working capabilities of such feature with a distributed system, aka Apache Spark working in a cluster.
In a next post, I will review the capabilities of using kdb+ with an Apache Spark Cluster.